Gateway
Gateway overview
Conduktor Gateway is a network proxy for Apache Kafka, complete with an extensible and dynamic plugin mechanism that can be used to add technical and business logic on top of your existing Kafka deployment.
This can be used to provide functionality that is not available in Kafka natively, such as:
- Centrally configure encryption at the field-level or full payload, to secure your data during transit and at rest, before the cluster
- Mask sensitive data across topics and set access rules, so users only see what they’re authorized to
- Set granular RBAC controls to manage access and permissions for data at the cluster, team or individual level
- Leverage multi-tenancy with virtual clusters to optimize resources and reduce operational overheads
- Empower development teams to manage their data within a federated control framework, accelerating project delivery
Conduktor Gateway is vendor-agnostic, meaning it supports all Kafka providers (Confluent, AWS MSK, Redpanda, Aiven, Apache Kafka), both cloud and on-premise.
To discover all functionality, see Gateway demos.
How it works
Conduktor Gateway is deployed between your client applications and existing Kafka clusters. As it's Kafka protocol compliant, there are minimal adjustments required for clients other than pointing to a new bootstrap server.
[Conduktor Gateway]
Authentication
Much like Kafka brokers, Gateway supports multiple security protocols for Kafka client to Gateway authentication, such as PLAINTEXT, SSL, SASL SSL, mTLS. Equally, Gateway supports all Kafka security protocols for Gateway to Kafka authentication. Read more about Gateway to Kafka Authentication or Client to Gateway Authentication.
Interceptors
Once Gateway is deployed, interceptors are used to add technical and business logic, such as message encryption, inside your Gateway deployment. Interceptors can be deployed and managed through the HTTP API, and targeted at a different scope (Global, Virtual Cluster, Group, Username). Read more about Interceptors.
Processing Flow
Kafka protocol requests, such as Produce requests, pass sequentially through each of the components in the pipeline, before being forwarded to the broker. When the broker returns a response, such as a Produce response, the components in the pipeline are invoked in reverse order, each having the opportunity to inspect and/or manipulate the response. Eventually, a response is returned to the client.
What about scaling?
The Gateway is stateless and can be scaled horizontally by adding more instances and distributing the incoming traffic using a load balancer.
What about resilience?
Much like Kafka, if a broker dies it can be restarted whilst Gateway keeps running. As the Gateway is Kafka protocol compliant, your applications remain available.
What about latency?
By default, the Gateway operates with minimal impact on performance, typically adding only milliseconds of latency. However, if you begin implementing more resource-intensive features, such as encryption utilizing a Key Management Service (KMS), there will naturally be a slight increase in overhead.
Resources
- Get started
- Concepts
- Configuration
- Support
- Arrange a technical demo
- Try demos yourself
- Release notes
Configure Gateway
Configuring Conduktor Gateway involves making decisions regarding several subjects.
- Configure your network.
- Define load balancing requirements.
- Connect Gateway to Kafka.
- Configure Gateway to accept client connections.
- Decide whether you need Virtual Clusters.
We also recommend that you Configure Gateway for failover.
1. Network configuration
When configuring Conduktor Gateway for the first time, selecting the appropriate routing method is crucial for optimizing your Kafka proxy setup. Pick one of these solutions depending on your requirements:
Choose port-based routing if your environment:
- doesn't require TLS encryption
- has flexible network port management capabilities
- prefers a simpler, straightforward configuration without DNS complexities
Choose host-based routing (SNI) if your environment:
- requires TLS encrypted connections for secure communication
- faces challenges with managing multiple network ports
- seeks a scalable solution with easier management of routing through DNS and host names
Port-Based routing
In port-based Routing, each Kafka broker is assigned a unique port number and clients connect to the appropriate port to access the required broker.
Gateway listens on as many ports as defined by the environment variable GATEWAY_PORT_COUNT. The recommended number of ports in production is double the amount of the Kafka brokers (to cover the growth of the Kafka cluster).
Configure port-based routing using these environment variables:
GATEWAY_ADVERTISED_HOSTGATEWAY_PORT_STARTGATEWAY_PORT_COUNTGATEWAY_MIN_BROKERID
The default port range values cover the range of the brokerIds with an additional two ports.
The maximum broker ID is requested from the cluster, the min should be set as GATEWAY_MIN_BROKERID. E.g., in a three broker cluster with IDs 1, 2, 3, GATEWAY_MIN_BROKERID should be set to 1 and the default port count will be 5.
We recommend SNI routing when not using a sequential and stable broker IDs range to avoid excessive port assignment. E.g., a three broker cluster with IDs 100, 200, 300 with GATEWAY_MIN_BROKERID=100 will default to 203 ports and would fail if broker ID 400 is introduced.
Host-based routing (SNI)
With host-based routing, Gateway listens on a single port and leverages Server Name Indication (SNI) (an extension to the TLS protocol), to route traffic based on the hostname specified in the TLS handshake to determine the target Kafka broker, requiring valid TLS certificates, proper DNS setup, and DNS resolution. Find out how to set up SNI routing.
2. Define load balancing
To map the different Gateway nodes sharing the same cluster and your Kafka brokers, you can either use:
- Gateway internal load balancing or
- an external load balancing
These options are only for the Kafka protocol, as any of the Gateway nodes can manage HTTP calls to their API.
Internal load balancing
Gateway's ability to distribute the client connections between the different Gateway nodes in the same cluster is what we refer to as internal load balancing. This is done automatically by Gateway and is the default behavior.
To deploy multiple Gateway nodes as part of the same Gateway cluster, you have to set the same GATEWAY_CLUSTER_ID in each node's deployment configuration. This configuration ensures that all nodes join the same consumer group, enabling them to consume the internal license topic from your Kafka cluster. This is how the nodes recognize each other as members of the same Gateway cluster.
When a client connects to one of the Gateway nodes to request metadata, the following process occurs (assuming GATEWAY_FEATURE_FLAGS_INTERNAL_LOAD_BALANCING is set to true, which is the default setting):
- The client chooses one of the bootstrap servers to ask for metadata.
- The Gateway node generates a mapping between its cluster nodes and the Kafka brokers.
- The Gateway node returns this mapping to the client.
- With the mapping in hand, the client can efficiently route its requests. For instance, if the client needs to produce to a partition where broker 3 is the leader, it knows to forward the request to Gateway 2 on port 9094.
For example, you have a Gateway cluster composed of two Gateway nodes, connected to a Kafka cluster with three brokers. The client's metadata discovery process might look like this:
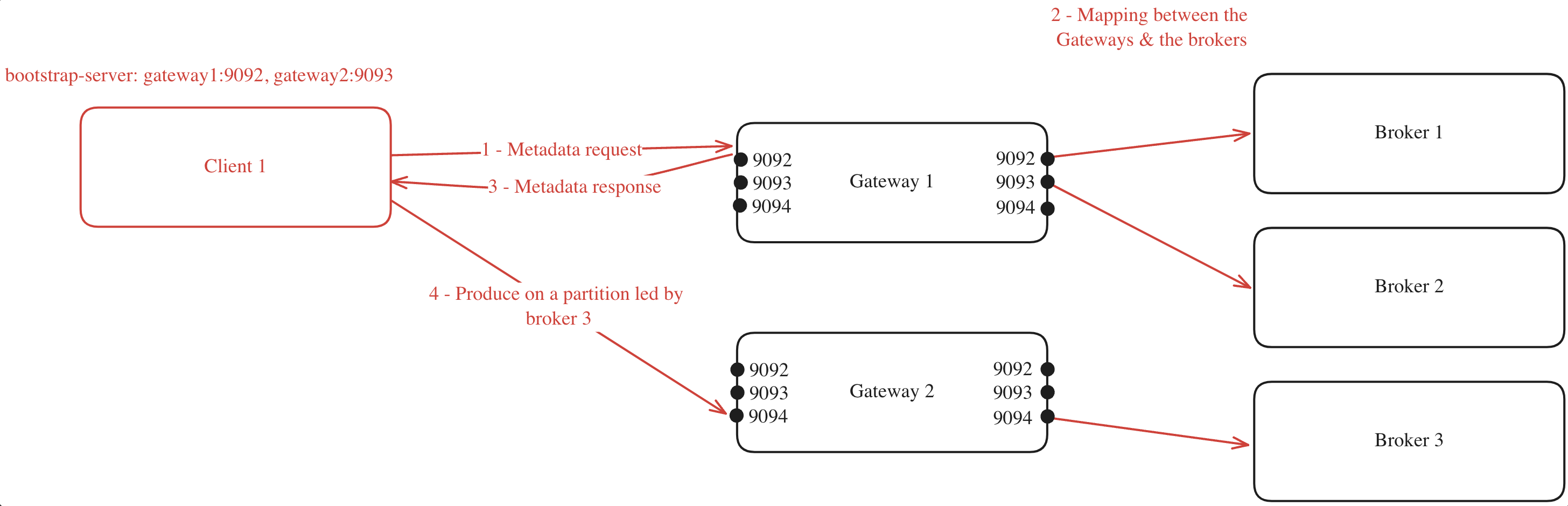
This mapping will be made again for every client asking for metadata, and will be made again as soon as a Gateway node is added or removed from the Gateway cluster.
If you have specified a GATEWAY_RACK_ID, then the mapping will take this into consideration and a Gateway node in the same rack as the Kafka broker will be assigned.
Here's the same example but with multiple clients:
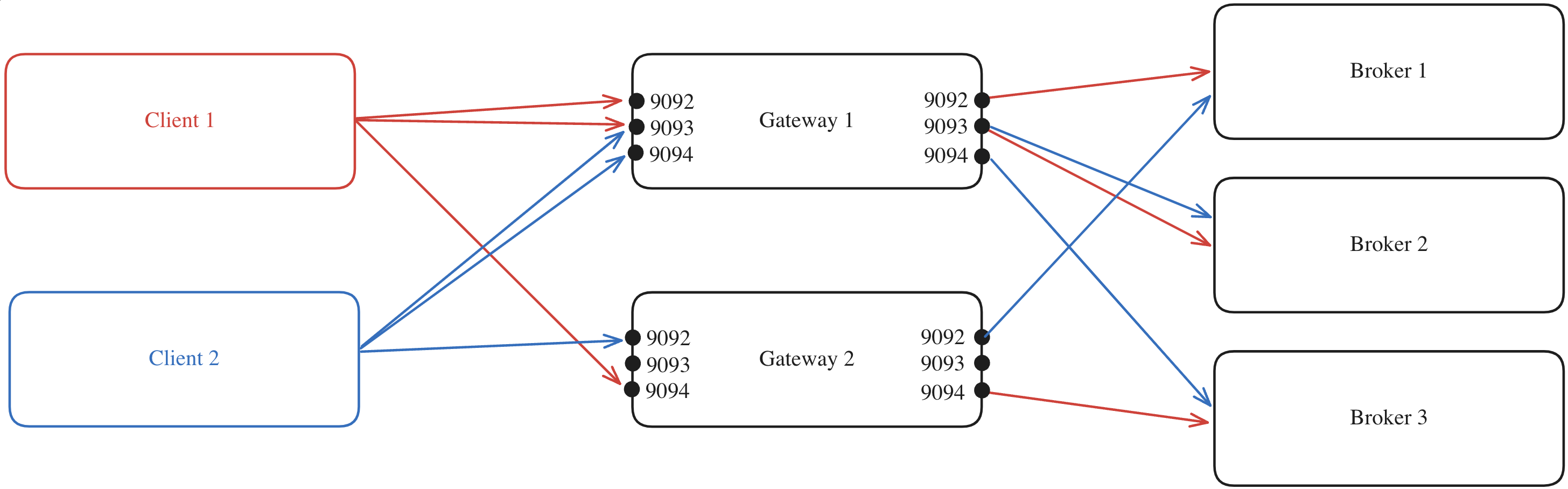
The process is repeated but will likely result in a different mapping compared to that of Client 1 due to the random assignment performed by the Gateway for the client.
Internal load balancing limitations
In a Kubernetes environment, your ingress must point at a single service, which could be an external load balancer as detailed below.
External load balancing
Alternatively, you can disable the internal load balancing by setting GATEWAY_FEATURE_FLAGS_INTERNAL_LOAD_BALANCING: false.
In this case, you would deploy your own load balancer, such as HAProxy, to manage traffic distribution. This would allow you to configure the stickiness of the load balancer as required.
Here's an example where:
- All client requests are directed to the external load balancer which acts as the entry point to your Gateway cluster.
- The load balancer forwards each request to one of the Gateway nodes, regardless of the port.
- The selected Gateway node, which knows which broker is the leader of each partition, forwards the request to the appropriate Kafka broker.
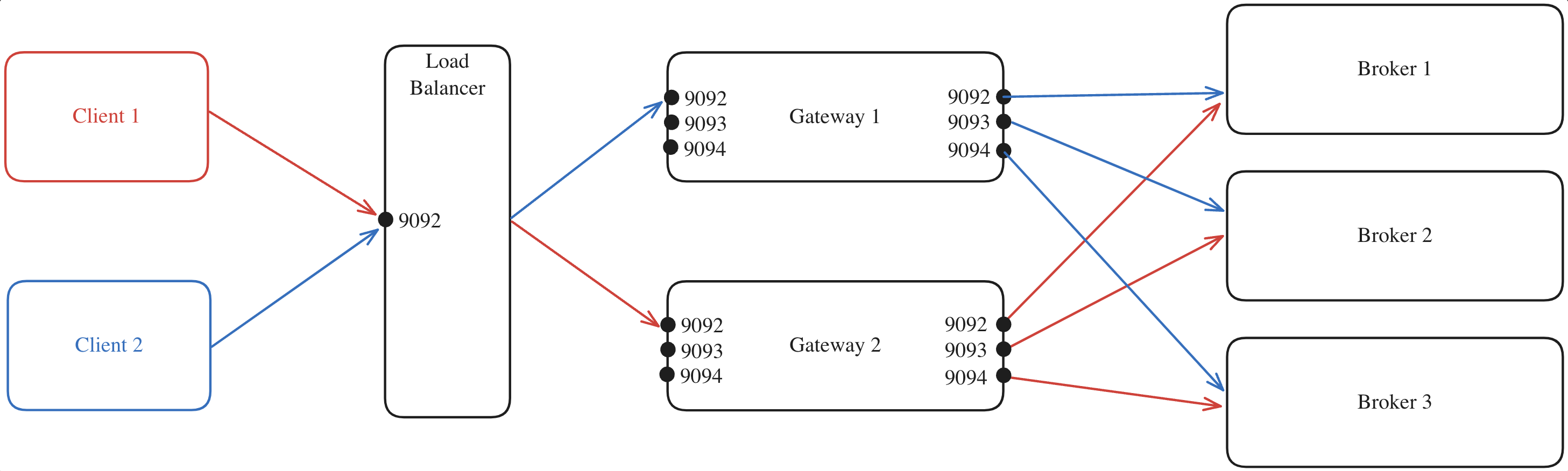
When using an external load balancer, you must configure the GATEWAY_ADVERTISED_LISTENER of the Gateway nodes to the Load Balancer's hostname. If this isn't done, applications will attempt to connect directly to Gateway, bypassing the Load Balancer.
External load balancing limitations
This requires you to handle load balancing manually, as you won't have the advantage of the automatic load balancing offered by Gateway's internal load balancing feature.
3. Connect Gateway to Kafka

Gateway depends on a 'backing' Kafka cluster for its operation.
Configuring the Gateway connection to the backing Kafka cluster closely resembles configuring a standard Kafka client's connection to a cluster.
If you've not done so already, it's best to set the client to Gateway configuration variables, that way the Gateway will know how to interact with Kafka based on how authentication is being provided by the clients, the two are related because Gateway must know whether you wish to use delegated authentication or not.
The configuration is done via environment variables, as it is for the other aspects of a Gateway configuration.
All environment variables that start with KAFKA_ are mapped to configuration properties for connecting Gateway to the Kafka cluster.
As Gateway is based on the Java-based Kafka-clients, it supports all configuration properties that Java-clients do. Kafka configuration properties are mapped to Gateway environment variables as follows:
- Add a
KAFKA_prefix - Replace each dot,
., with an underscore,_ - Convert to uppercase
For example, bootstrap.servers is set by the KAFKA_BOOTSTRAP_SERVERS environment variable.
Supported protocols
You can use all the Kafka security protocols to authenticate Gateway to the Kafka cluster; PLAINTEXT, SASL_PLAINTEXT, SASL_SSL and SSL.
These can be used with all SASL mechanisms supported by Apache Kafka: PLAIN, SCRAM-SHA, OAuthBearer, Kerberos etc. In addition, we support IAM authentication for AWS MSK clusters.
In the following examples, we provide blocks of environment variables which can be provided to Gateway, e.g. in a docker-compose file, or a helm deployment.
Information which should be customized is enclosed by < and >.
PLAINTEXT
Kafka cluster without authentication or encryption in transit, PLAINTEXT.
In this case you just need the bootstrap servers:
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
SSL
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SSL
KAFKA_SASL_MECHANISM: PLAIN
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.plain.PlainLoginModule required username="<gw-sa-username>" password="<gw-sa-password>";
KAFKA_SSL_TRUSTSTORE_TYPE: <JKS>
KAFKA_SSL_TRUSTSTORE_LOCATION: </path/to/truststore.jks>
KAFKA_SSL_TRUSTSTORE_PASSWORD: <truststore-password>
KAFKA_SSL_KEYSTORE_TYPE: <JKS>
KAFKA_SSL_KEYSTORE_LOCATION: </path/to/keystore.jks>
KAFKA_SSL_KEYSTORE_PASSWORD: <keystore-password>
KAFKA_SSL_KEY_PASSWORD: <key-password>
mTLS
Kafka cluster with mTLS client authentication.
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>, <your.kafka.broker-3:9092>
KAFKA_SECURITY_PROTOCOL: SSL
KAFKA_SSL_TRUSTSTORE_LOCATION: /security/truststore.jks
KAFKA_SSL_TRUSTSTORE_PASSWORD: conduktor
KAFKA_SSL_KEYSTORE_LOCATION: /security/kafka.gw.keystore.jks
KAFKA_SSL_KEYSTORE_PASSWORD: conduktor
KAFKA_SSL_KEY_PASSWORD: conduktor
SASL_PLAINTEXT
Kafka cluster with SASL_PLAINTEXT security protocol but no encryption in transit, supporting the following SASL_MECHANISMs.
SASL PLAIN
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SASL_PLAINTEXT
KAFKA_SASL_MECHANISM: PLAIN
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.plain.PlainLoginModule required username="<gw-sa-username>" password="<gw-sa-password>";
SASL SCRAM
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SASL_PLAINTEXT
KAFKA_SASL_MECHANISM: SCRAM-SHA-256 # or SCRAM-SHA-512
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.scram.ScramLoginModule required username="<gw-sa-username>" password="<gw-sa-password>";
OAuthbearer
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SASL_PLAINTEXT
KAFKA_SASL_MECHANISM: OAUTHBEARER
KAFKA_SASL_OAUTHBEARER_TOKEN_ENDPOINT_URL: "<https://myidp.example.com/oauth2/default/v1/token>"
KAFKA_SASL_LOGIN_CALLBACK_HANDLER_CLASS: org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId=“<>” clientSecret=“<>” scope=“.default”;
SASL_SSL
Kafka cluster that uses SASL for authentication and TLS (formerly SSL) for encryption in transit.
PLAIN
Kafka cluster with SASL_SSL and PLAIN SASL mechanism.
Confluent Cloud with API key/secret
This example can be seen as a special case of the above.
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.cluster.confluent.cloud:9092>
KAFKA_SECURITY_PROTOCOL: SASL_SSL
KAFKA_SASL_MECHANISM: PLAIN
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.plain.PlainLoginModule required username="<API_KEY>" password="<API_SECRET>";
As Confluent Cloud uses certificates signed by a well-known CA, you normally do not need to specify a trust-store.
Note: In case you are using this in a PoC setting without TLS encryption between clients and Gateway, you should set GATEWAY_SECURITY_PROTOCOL to DELEGATED_SASL_PLAINTEXT. Clients will then be able to authenticate using their own API keys/secrets.
SASL SCRAM
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SASL_SSL
KAFKA_SASL_MECHANISM: SCRAM-SHA-256 # or SCRAM-SHA-512
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.scram.ScramLoginModule required username="<gw-sa-username>" password="<gw-sa-password>";
KAFKA_SSL_TRUSTSTORE_TYPE: <JKS>
KAFKA_SSL_TRUSTSTORE_LOCATION: </path/to/truststore.jks>
KAFKA_SSL_TRUSTSTORE_PASSWORD: <truststore-password>
SASL GSSAPI (Kerberos)
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SASL_SSL
KAFKA_SASL_MECHANISM: GSSAPI
KAFKA_SASL_JAAS_CONFIG: com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab="<>>" principal="<>";
KAFKA_SASL_KERBEROS_SERVICE_NAME: <kafka>
KAFKA_SSL_TRUSTSTORE_TYPE: <JKS>
KAFKA_SSL_TRUSTSTORE_LOCATION: </path/to/truststore.jks>
KAFKA_SSL_TRUSTSTORE_PASSWORD: <truststore-password>
OAuthbearer
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT
KAFKA_BOOTSTRAP_SERVERS: <your.kafka.broker-1:9092>,<your.kafka.broker-2:9092>
KAFKA_SECURITY_PROTOCOL: SASL_SSL
KAFKA_SASL_MECHANISM: OAUTHBEARER
KAFKA_SASL_OAUTHBEARER_TOKEN_ENDPOINT_URL: "<https://myidp.example.com/oauth2/default/v1/token>"
KAFKA_SASL_LOGIN_CALLBACK_HANDLER_CLASS: org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler
KAFKA_SASL_JAAS_CONFIG: org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId=“<>” clientSecret=“<>” scope=“.default”;
AWS MSK cluster with IAM
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT # Change to relevant client-side value if known
KAFKA_BOOTSTRAP_SERVERS: <b-3-public.****.kafka.eu-west-1.amazonaws.com:9198>
KAFKA_SECURITY_PROTOCOL: SASL_SSL
KAFKA_SASL_MECHANISM: AWS_MSK_IAM
KAFKA_SASL_JAAS_CONFIG: software.amazon.msk.auth.iam.IAMLoginModule required;
KAFKA_SASL_CLIENT_CALLBACK_HANDLER_CLASS: io.conduktor.aws.IAMClientCallbackHandler
KAFKA_AWS_ACCESS_KEY_ID: <access-key-id>
KAFKA_AWS_SECRET_ACCESS_KEY: <secret-access-key>
Service account and ACL requirements
Depending on the client to Gateway authentication method you choose, the service account used to connect the Gateway might need different ACLs to operate properly.
Delegated authentication
In delegated authentication, the credentials provided to establish the connection between the client and the Gateway are the same used from Gateway to the backing Kafka. As a result, the client will inherit the ACLs of the service account configured on the backing cluster.
On top of that, Gateway needs its own service account with the following ACLs to operate correctly:
Readon internal topics and they should exist- Describe consumer group for internal topic
- Describe on cluster
- Describe topics for alias topics creation
Non-delegated
In non-delegated authentication (Local, Oauth or mTLS), the connection is using Gateway's service account to connect to the backing Kafka.
This service account must have all the necessary ACLs to perform not only these Gateway operations:
Readon internal topics and they should exist- Describe consumer group for internal topic
- Describe on cluster
- Describe topics for alias topics creation but also all the permissions necessary to serve all Gateway users.
If necessary, you can enable ACLs for non-delegated authentication.
First, configure GATEWAY_ACL_STORE_ENABLED=true and then you can use AdminClient to maintain ACLs with any service account declared in GATEWAY_ADMIN_API_USERS.
4. Configure Gateway to accept client connections
Gateway brokers support multiple security schemes for Kafka clients to connect with. Each section has specific details of the available options, how they work and how to configure them. Pick the most suitable option based on the nature of your system's requirements, design and constraints.
The authentication phase on Gateway is part of the initial communication handling by Gateway to handshake, and authenticate, a Kafka client. This phase manages the encryption of the network communication and how to identify a client.
All open connections in Gateway result in a Principal that represents the authenticated identity of the Kafka client.
We can split this authentication and security configuration into two aspects:
- Security protocol: defines how a Kafka client and Gateway broker should communicate and secure the connection.
- Authentication mechanism: defines how a client can authenticate itself when opening the connection.
Supported security protocols:
- PLAINTEXT: Brokers don't need client authentication; all communication is exchanged without network security.
- SSL: With SSL-only clients don't need any client authentication but communication between the client and Gateway broker will be encrypted.
- mTLS: This security protocol is not originally intended to provide authentication, but you can use the mTLS option below to enable an authentication. mTLS leverages SSL mutual authentication to identify a Kafka client.
Principalfor mTLS connection can be detected from the subject certificate using the same feature as in Apache Kafka, the SSL principal mapping. - SASL PLAINTEXT: Brokers don't need any client authentication and all communication is exchanged without any network security.
- SASL SSL: Authentication from the client is mandatory against Gateway and communication will be encrypted using TLS.
- DELEGATED_SASL_PLAINTEXT: Authentication from the client is mandatory but will be forwarded to Kafka for checking. Gateway will intercept exchanged authentication data to detect authenticated principals:
- All communication between the client and gateway broker is exchanged without any network security.
- All credentials are managed by your backend kafka, we only provide authorization on the Gateway side based on the exchanged principal.
| Clients ⟶ GW transit in plaintext | Clients ⟶ GW transit is encrypted | |
|---|---|---|
| Anonymous access only | Security protocol: PLAINTEXTAuthentication mechanism: None | Security protocol: SSLAuthentication mechanism: None |
| Credentials managed by Gateway | Security protocol: SASL_PLAINTEXTAuthentication mechanism: PLAIN | Security protocol: SASL_SSLAuthentication mechanism: PLAIN |
| Gateway configured with OAuth | Security protocol: SASL_PLAINTEXTAuthentication mechanism: OAUTHBEARER | Security protocol: SASL_SSLAuthentication mechanism: OAUTHBEARER |
| Clients are identified by certificates (mTLS) | Not possible (mTLS means encryption) | Security protocol: SSLAuthentication mechanism: MTLS |
| Credentials managed by Kafka | Security protocol: DELEGATED_SASL_PLAINTEXTAuthentication mechanism: PLAIN, SCRAM-SHA-256, SCRAM-SHA-512, OAUTHBEARER orAWS_MSK_IAM | Security protocol: DELEGATED_SASL_SSLAuthentication mechanism: PLAIN, SCRAM-SHA-256, SCRAM-SHA-512, OAUTHBEARER orAWS_MSK_IAM |
Security protocol
The Gateway broker security scheme is defined by the GATEWAY_SECURITY_PROTOCOL configuration.
Note that you don't set an authentication mechanism on the client to Gateway side of the proxy, i.e. GATEWAY_SASL_MECHANISM does not exist and is never configured by the user. Instead, Gateway will try to authenticate the client as it presents itself.
For example, if a client is using OAUTHBEARER, Gateway will use the OAuth configuration to try authenticate it. If a client arrives using PLAIN, Gateway will try use either the SSL configuration or validate the token itself, depending on the security protocol.
In addition to all the security protocols that Apache Kafka supports, Gateway adds two new protocols:DELEGATED_SASL_PLAINTEXT and DELEGATED_SASL_SSL for delegating to Kafka.
PLAINTEXT
There is no client authentication to Gateway and all communication is exchanged without any network security.
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: PLAINTEXT
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=PLAINTEXT
SSL
With SSL only, there is no client authentication, but communication between the client and Gateway broker will be encrypted.
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: SSL
GATEWAY_SSL_KEY_STORE_PATH: /path/to/your/keystore.jks
GATEWAY_SSL_KEY_STORE_PASSWORD: yourKeystorePassword
GATEWAY_SSL_KEY_PASSWORD: yourKeyPassword
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=SSL
ssl.truststore.location=/path/to/your/truststore.jks
ssl.truststore.password=yourTruststorePassword
ssl.protocol=TLSv1.3
The truststore contains certificates from trusted Certificate Authorities (CAs) used to verify the Gateway's TLS certificate, which is stored in the keystore. Find out more about jks truststores.
Mutual TLS (mTLS)
Mutual TLS leverages client side certificates to authenticate a Kafka client.
Principal for an mTLS connection can be detected from the subject of the certificate using the same feature as Apache Kafka, the SSL principal mapping .
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: SSL
GATEWAY_SSL_CLIENT_AUTH: REQUIRE
GATEWAY_SSL_KEY_STORE_PATH: /path/to/your/keystore.jks
GATEWAY_SSL_KEY_STORE_PASSWORD: yourKeystorePassword
GATEWAY_SSL_KEY_PASSWORD: yourKeyPassword
GATEWAY_SSL_TRUST_STORE_PATH: /path/to/your/truststore.jks
GATEWAY_SSL_TRUST_STORE_PASSWORD: yourTrustStorePassword
Client configuration:
bootstrap.servers=your.gateway.hostname:9093
security.protocol=SSL
ssl.keystore.type=PEM
ssl.keystore.key=/path/to/your/client.key
ssl.keystore.certificate.chain=/path/to/your/client.crt
ssl.truststore.type=PEM
ssl.truststore.certificates=/path/to/your/ca.crt
ssl.protocol=TLSv1.3
ssl.client.auth=required
The server CA certificate here is provided as a PEM file as well as the client's certificates (ssl.keystore.xx keys). Jks could also be used for both client and server side authentication.
SASL_PLAINTEXT
Authentication from the client is mandatory against Gateway but all communications are exchanged without any network security. Gateway supports Plain and OAuthbearer SASL mechanisms.
Plain
Plain mechanism uses Username/Password credentials to authenticate credentials against Gateway. Plain credentials take the form of a JWT token, these are managed in Gateway using the Admin (HTTP) API. See below for the creation of tokens.
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: SASL_PLAINTEXT
GATEWAY_USER_POOL_SECRET_KEY: yourRandom256bitKeyUsedToSignTokens
TheGATEWAY_USER_POOL_SECRET_KEY has to be set to a random base64 encoded value of 256bits long to ensure that tokens aren't forged. For example: openssl rand -base64 32. Otherwise, a default value for signing tokens will be used.
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="yourUsername" \
password="yourToken";
It has to be a token that's obtained by a Gateway admin via the Admin (HTTP) API, as follows:
- Create the service account, the username
Request:
curl \
--request PUT \
--url 'http://localhost:8888/gateway/v2/service-account' \
--user admin:conduktor \
--header 'Content-Type: application/json' \
--data-raw '{
"kind" : "GatewayServiceAccount",
"apiVersion" : "gateway/v2",
"metadata" : {
"name" : "jdoe",
"vCluster" : "passthrough"
},
"spec" : { "type" : "LOCAL" }'
Response:
{
"resource" : {
"kind" : "GatewayServiceAccount",
"apiVersion" : "gateway/v2",
"metadata" : {
"name" : "jdoe",
"vCluster" : "passthrough"
},
"spec" : {
"type" : "LOCAL"
}
},
"upsertResult" : "CREATED"
}
- Generate a token for the service account, the password
Request:
curl \
--silent \
--request POST \
--url 'http://localhost:8888/gateway/v2/token' \
--header 'Authorization: Basic YWRtaW46Y29uZHVrdG9y' \
--header 'Content-Type: application/json' \
--data-raw '{
"username": "jdoe",
"vCluster": "passthrough",
"lifeTimeSeconds": 3600000
}'
{"token":"eyJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6Impkb2UiLCJ2Y2x1c3RlciI6InBhc3N0aHJvdWdoIiwiZXhwIjoxNzQ1MzY1OTcxfQ.zPPiD17MiRnXyHJw07Cx4SKPySDi_ErJrXmi5BycR04"}
The token conforms to the JWT token specification. The JWT payload contains the username, the vCluster and the expiration date:
jwt decode eyJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6Impkb2UiLCJ2Y2x1c3RlciI6InBhc3N0aHJvdWdoIiwiZXhwIjoxNzQ1MzY1OTcxfQ.zPPiD17MiRnXyHJw07Cx4SKPySDi_ErJrXmi5BycR04
Token claims
------------
{
"exp": 1745365971,
"username": "jdoe",
"vcluster": "passthrough"
}
OAuthbearer
Oauthbearer uses a OAuth2/OIDC security provider to authenticate a token in Gateway. The Oauth credentials base is managed in the configured provider.
This mechanism will also allow you to verify some claims from your OIDC provider ( audience and issuer ).
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: SASL_PLAINTEXT
GATEWAY_OAUTH_JWKS_URL: https://login.microsoftonline.com/common/discovery/keys
GATEWAY_OAUTH_EXPECTED_ISSUER: https://sts.windows.net/xxxxxxxx-df00-48cd-805b-1ebe914e8b11/
GATEWAY_OAUTH_EXPECTED_AUDIENCES: "[00000002-0000-0000-c000-000000000000]"
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=SASL_PLAINTEXT
sasl.mechanism=OAUTHBEARER
sasl.login.callback.handler.class=org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler
sasl.oauthbearer.token.endpoint.url=https://login.microsoftonline.com/xxxxxxxx-df00-48cd-805b-1ebe914e8b11/oauth2/token
sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
clientId="yourClientID" \
clientSecret="yourClientSecret" \
scope=".default";
SASL_SSL
Authentication from client is mandatory against Gateway and communication will be encrypted using TLS. Supported authentication mechanisms:
- PLAIN
- OAUTHBEARER
Plain
Plain mechanism use Username/Password credentials to authenticate credentials against Gateway. Plain credentials are managed in Gateway using the HTTP API.
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: SASL_SSL
GATEWAY_USER_POOL_SECRET_KEY: yourRandom256bitKeyUsedToSignTokens
GATEWAY_SSL_KEY_STORE_PATH: /path/to/your/keystore.jks
GATEWAY_SSL_KEY_STORE_PASSWORD: yourKeystorePassword
GATEWAY_SSL_KEY_PASSWORD: yourKeyPassword
You have to set GATEWAY_USER_POOL_SECRET_KEY to a random value to ensure that tokens cannot be forged. Otherwise, a default value for signing tokens will be used.
Client configuration:
bootstrap.servers=your.gateway.hostname:9093
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
ssl.truststore.location=/path/to/your/truststore.jks
ssl.truststore.password=yourTruststorePassword
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="yourUsername" \
password="yourToken";
See the above section for requirements on how to create tokens using the Admin (HTTP) API.
OAuthbearer
Oauthbearer uses a OAuth2/OIDC security provider to authenticate a token in Gateway. The Oauth credentials base is managed in the configured provider.
This mechanism will also allow you to verify some claims from your OIDC provider ( audience and issuer ).
Gateway configuration:
GATEWAY_SECURITY_PROTOCOL: SASL_SSL
GATEWAY_OAUTH_JWKS_URL: https://login.microsoftonline.com/common/discovery/keys
GATEWAY_OAUTH_EXPECTED_ISSUER: https://sts.windows.net/xxxxxxxx-df00-48cd-805b-1ebe914e8b11/
GATEWAY_OAUTH_EXPECTED_AUDIENCES: "[00000002-0000-0000-c000-000000000000]"
GATEWAY_SSL_KEY_STORE_PATH: /path/to/your/keystore.jks
GATEWAY_SSL_KEY_STORE_PASSWORD: yourKeystorePassword
GATEWAY_SSL_KEY_PASSWORD: yourKeyPassword
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=SASL_SSL
sasl.mechanism=OAUTHBEARER
ssl.truststore.location=/path/to/your/truststore.jks
ssl.truststore.password=yourTruststorePassword
sasl.login.callback.handler.class=org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler
sasl.oauthbearer.token.endpoint.url=https://login.microsoftonline.com/xxxxxxxx-df00-48cd-805b-1ebe914e8b11/oauth2/token
sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
clientId="yourClientID" \
clientSecret="yourClientSecret" \
scope=".default";
DELEGATED_SASL_PLAINTEXT
Authentication from client is mandatory but will be forwarded to Kafka for checking. Gateway will intercept exchanged authentication data to detect an authenticated principal:
- All communication between the client and Gateway broker are exchanged without any network security.
- All credentials are managed by your backing Kafka, we only provide Authorization on the Gateway side based on the exchanged principal.
Supported authentication mechanisms on the backing Kafka are:
- PLAIN
- SCRAM-SHA-256
- SCRAM-SHA-512
- OAUTHBEARER
- AWS_MSK_IAM
Gateway configuration: using PLAIN, as used for example on Confluent Cloud:
GATEWAY_SECURITY_PROTOCOL: DELEGATED_SASL_PLAINTEXT
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="yourKafkaUser" password="yourKafkaPassword";
DELEGATED_SASL_SSL
Authentication from the client is mandatory but will be forwarded to Kafka. Gateway will intercept exchanged authentication data to detect an authenticated principal:
- All communication between the client and Gateway broker will be encrypted using TLS.
- All credentials are managed by your backing Kafka, we only provide Authorization on the Gateway side based on the exchanged principal.
Supported authentication mechanisms on the backing Kafka are:
- PLAIN
- SCRAM-SHA-256
- SCRAM-SHA-512
- OAUTHBEARER
- AWS_MSK_IAM
Gateway configuration using PLAIN, as used for example on Confluent Cloud:
GATEWAY_SECURITY_PROTOCOL: DELEGATED_SASL_SSL
GATEWAY_SSL_KEY_STORE_PATH: /path/to/your/keystore.jks
GATEWAY_SSL_KEY_STORE_PASSWORD: yourKeystorePassword
GATEWAY_SSL_KEY_PASSWORD: yourKeyPassword
Client configuration:
bootstrap.servers=your.gateway.hostname:9092
security.protocol=SASL_SSL
ssl.truststore.location=/path/to/your/truststore.jks
ssl.truststore.password=yourTruststorePassword
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="yourKafkaUser" password="yourKafkaPassword";
Automatic security protocol detection (default behavior)
On startup Gateway will attempt to detect the security protocol to use based on the Kafka configuration if you don't specify any security protocol. If there's also no security protocol on the backing Kafka cluster, then we set the security protocol to PLAINTEXT by default.
Here's our mapping from the Kafka cluster's defined protocol:
| Kafka cluster security protocol | Gateway cluster inferred security protocol |
|---|---|
| SASL_SSL | DELEGATED_SASL_SSL |
| SASL_PLAINTEXT | DELEGATED_SASL_PLAINTEXT |
| SSL | SSL |
| PLAINTEXT | PLAINTEXT |
Note that you can always see the inferred security protocol on the startup log of Gateway.
2025-03-07T15:40:12.260+0100 [ main] [INFO ] [Bootstrap:70] - Computed configuration :
---
gatewayClusterId: "gateway"
...
authenticationConfig:
securityProtocol: "SASL_PLAINTEXT"
sslConfig:
...
Re-authentication support
We support Apache Kafka Re authentication as Kafka brokers. See KIP-368 for details.
5. Decide on Virtual Clusters
A Virtual Cluster in Conduktor Gateway is a logical representation of a Kafka cluster.
This allows you to create multiple virtual clusters while maintaining a single physical Kafka cluster, enabling the simulation of multiple Kafka environments on a single physical infrastructure.
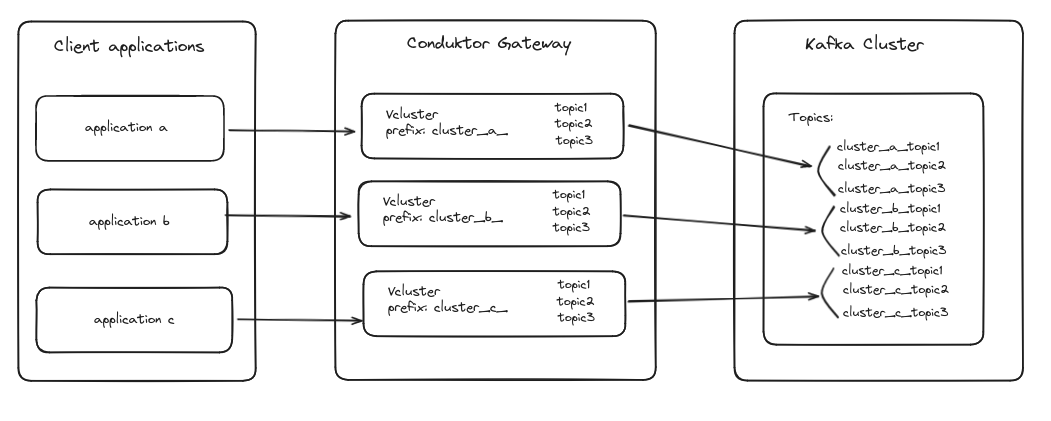
Virtual Clusters are entirely optional. If you choose to not configure any, Conduktor Gateway will act as a transparent proxy for your backing Kafka Cluster. This is the default mode and all topics/resources will be visible and accessible as usual, without any additional configuration.
Benefits
Flexibility and scalability: Virtual Clusters provide the flexibility to simulate multiple independent Kafka clusters without the need for additional physical resources. This is particularly useful for environments where different teams or applications require separate Kafka instances but maintaining multiple physical clusters would be cost-prohibitive or complex.
Isolation and multitenancy: By using Virtual Clusters, you can ensure isolation between different logical clusters, similar to enabling multitenancy in Kafka. Each Virtual Cluster can have its own set of topics and consumer groups, and these are managed independently even though they reside on the same physical cluster.
Resource efficiency: Instead of deploying and managing multiple physical clusters, which can be resource-intensive and expensive, Virtual Clusters allow you to maximize the utilization of a single physical Kafka cluster. This leads to better resource management and operational efficiency.
Example
When you create a Virtual Cluster in Conduktor Gateway, it prefixes all resources (such as topics and consumer groups) associated with that Virtual Cluster on the backing physical Kafka cluster.
This prefixing ensures that there's no overlap or conflict between resources belonging to different Virtual Clusters, thereby maintaining their isolation.
In the example below, we assume a topic order has been created on Virtual Cluster vc-alice. Let's see how other Virtual Clusters and Backing cluster perceive this:
# Listing topics on Virtual Cluster vc-alice
$ kafka-topics --bootstrap-server=gateway:6969 --command-config vc-alice.properties --list
orders
# As expected, Alice sees its topic normally.
# Now let's check what happens if we list the topics with Bob
$ kafka-topics --bootstrap-server=gateway:6969 --command-config vc-bob.properties --list
[]
# Bob doesn't see Alice's topics.
# Let's try to create the same topic for Bob
$ kafka-topics --bootstrap-server=gateway:6969 --command-config vc-bob.properties --create --topic orders
$ kafka-topics --bootstrap-server=gateway:6969 --command-config vc-bob.properties --list
orders
# If we contact directly the backing cluster instead of the gateway,
# we can see both topics under a different name. This is the actual topic name on the Kafka cluster, which is observed when not interacting through the Gateway.
$ kafka-topics.sh --bootstrap-server=backing-kafka:9092 --list
vc-alice.orders
vc-bob.orders
Configure Gateway for failover
In a disaster recovery or business continuity scenario, we want to be able to switch clients from one Kafka cluster (the primary) to another one (the secondary) without having to reconfigure the clients.
Reconfiguring clients would at least involve changing the bootstrap servers of the clients, forcing the clients to refresh the metadata and retry all messages in flight. It might also involve distributing new credentials to the clients. For example, API keys and secrets in Confluent Cloud are tied to a specific cluster. Other Kafka providers might have different restrictions.
Essentially, this implies that the central operations/Kafka team (who would be responsible for initiating the failover-process) would have knowledge about all clients, which in practice is not feasible. The failover capability of Gateway solves this by redirecting client connections from the primary to the secondary cluster. This can be initiated at a central location using the Gateway HTTP API without having to reconfigure/restart each Kafka client individually.
Pre-requisites
Data replication is already in place
Gateway does not currently provide any mechanism to replicate already written data from the primary to the secondary cluster. Therefore, to make use of our solution, you should already have this mechanism in place. Common solutions for this include:
- MirrorMaker 2
- Confluent Replicator
- Confluent Cluster Linking
Note that none of these solutions (and therefore neither Conduktor's failover solution) can guarantee the absence of data loss during a disaster scenario.
Kafka client configuration
No specific client configuration is necessary, besides ensuring that clients have configured enough retries (or that the delivery.timeout.ms for JVM-based clients) setting is large enough to cover the time necessary for the operations team to discover failure of the primary cluster and initiate a failover procedure. Especially for JVM-based clients, the default delivery timeout of 2 minutes might be too short.
System requirements
- Gateway version
3.3.0+ - Kafka brokers version
2.8.2+
Note that due to a current limitation in Kafka clients, the primary and secondary Kafka clusters must have some broker id's in common (see KIP-899). This ensures clients can recognize the secondary cluster as a legitimate continuation of the primary one.
How it works
Conduktor Gateway acts as a 'hot-switch' to the secondary Kafka cluster, eliminating the need to change any client configurations in a disaster scenario. This is achievable because Gateway de-couples authentication between clients and the backing Kakfa cluster(s).
Note that to initiate failover, it must be triggered through an API request to every Gateway instance. The Conduktor team can support you in finding the best solution for initiating failover, depending on your deployment specifities.
![Failover]assets/failover-docs.png
Configuring Gateway
To set up Gateway for failover, you should configure the primary and secondary clusters along with their configuration properties. This can be achieved through a cluster-config file, or through environment variables.
Configuring through a cluster-config file
Specify your primary and secondary cluster configurations, along with a gateway.roles entry to mark the failover cluster - note that the API keys differ in the Confluent Cloud example below:
config:
main:
bootstrap.servers: <primary bootstrap address>:9092
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="<primary-api-key>" password="<primary-api-secret>";
failover:
bootstrap.servers: <secondary bootstrap address>:9092
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="<secondary-api-key>" password="<secondary-api-secret>";
gateway.roles: failover
Mount the cluster config file in the Gateway container using the configuration GATEWAY_BACKEND_KAFKA_SELECTOR:
GATEWAY_BACKEND_KAFKA_SELECTOR: 'file : { path: /cluster-config.yaml}'
Configuring through environment variables
Alternatively, you can configure your primary and secondary cluster through environment variables:
KAFKA_MAIN_BOOTSTRAP_SERVERS='<primary bootstrap address>:9092'
KAFKA_MAIN_SECURITY_PROTOCOL='SASL_SSL'
KAFKA_MAIN_SASL_MECHANISM='PLAIN'
KAFKA_MAIN_SASL_JAAS_CONFIG='org.apache.kafka.common.security.plain.PlainLoginModule required username="<primary-api-key>" password="<primary-api-secret>";'
KAFKA_FAILOVER_BOOTSTRAP_SERVERS='<secondary bootstrap address>:9092'
KAFKA_FAILOVER_SECURITY_PROTOCOL='SASL_SSL'
KAFKA_FAILOVER_SASL_MECHANISM='PLAIN'
KAFKA_FAILOVER_SASL_JAAS_CONFIG='org.apache.kafka.common.security.plain.PlainLoginModule required username="<secondary-api-key>" password="<secondary-api-secret>";'
KAFKA_FAILOVER_GATEWAY_ROLES='failover'
Initiating failover
To initiate failing over from the primary to the secondary cluster, the following request must be made to all Gateway instances:
curl \
--request POST 'http://localhost:8888/admin/pclusters/v1/pcluster/main/switch?to=failover' \
--user 'admin:conduktor' \
--silent | jq
Switching back
To switch back from the secondary cluster to the primary cluster, the following request must be made to all Gateway instances:
curl \
--request POST 'http://localhost:8888/admin/pclusters/v1/pcluster/main/switch?to=main' \
--user 'admin:conduktor' \
--silent | jq
Alternative solutions to switchover
Note that Conduktor can recommend alternative solutions for initiating the switchover that does not involve making an API call to every Gateway instance. These alternatives are dependent on your deployment configuration, therefore we recommend contacting us to discuss this.
Failover limitation
During a failover event, the following functionality will not work:
- Chargeback: Chargeback will only collect data for the original cluster. During a failover event data is not collected but would resume if failed back to the original cluster.